Apogee busts out multi-value cells using Tableau Prep Builder!

 |
Problem
If you have ever been handed unnormalized data containing multiple values crammed into single cells, then you know how frustrating it can be to analyze data with that (lack of) structure. Breaking values out of a single cell is a common practice in data science essential to understanding relationships between entities. Tableau’s new data model now supports relationships between tables at multiple levels of detail – assuming you can first wrangle your data into a normalized form.
If you need to split delimiter-separated values in a column into a table with separate rows, the options currently available in Tableau Prep are a bit limited. Luckily, we can now use Tableau Prep’s recent release of a script step to call a Python script to get an efficient and reliable way to split multiple valued columns.
The Flerlage Twins, both Tableau Zen Masters, published a blog article showing how to split and use pivot tables with Tableau Prep Builder.
Their solution gets the job done, but there are a couple of limitations.
- the approach is a bit cumbersome, requiring multiple steps that vary in complexity
- if you need to do this on many datasets, repeating the process can get tedious
- can be error prone & time consuming.
and some potentially serious issues:
- the split function in Tableau Prep requires a hard-coded maximum number of values that can appear in the column being split
- values beyond the hard-coded limit are silently dropped causing a loss of data
- no warning to the user.
Solution
As an alternative to hard-coded limits, potential data loss and in far less time, you can use the Python script below to take advantage of Pandas’ explode() function to break comma separated values into separate rows. CellSplitter is designed to be deployed via a TabPy server. If you are unfamiliar with the TabPy server or have questions about setting it up, The Information Lab UK has very clear and concise instructions for installation available here
def cellSplitter(df)
if 'Values' in df:
df['Values']=df['Values'].str.split(',')
exploded = df.filter(regex='Values|^Key').explode('Values')
exploded = exploded[exploded['Values'].str.strip().astype(bool)]
return exploded
else:
return df
def get_output_schema(inputSchema):
if 'Values' in inputSchema:
return pd.DataFrame(inputSchema.filter(regex='Values|^Key'))
else:
return pd.DataFrame(inputSchema)
Example Usage
Using the Sample Country dataset in Tableau Prep:
|
ID |
Country ID |
Birthplace |
Person ID |
|
1 |
C100 |
Germany |
P100 |
|
2 |
C200 |
USA |
P300, P400 |
|
3 |
C300 |
Morocco |
P500 |
|
4 |
C400 |
Spain |
P200, P700 |
|
5 |
C500 |
South Africa |
P600, P800, P900 |
Note: Tableau Prep currently does not allow for passing of arguments to functions – so, renaming columns tells the Python function which columns to split, preserve and output.
To execute the CellSplitter script in Tableau Prep to split the ‘Person ID’ column into separate rows for each value and include ‘ID’ and ‘Birthplace’ columns in the output unchanged:
- connect to the Sample Country Data set in Tableau Prep
- add a clean step to the data flow.
- rename the Person ID column to ‘Values’ (cellSplitter splits columns named ‘Values’)
- add the prefix ‘Key’ to columns to output unchanged (cellSplitter includes columns unchanged with the prefix ‘Key’)
|
Key ID |
Country ID |
Key Birthplace |
Values |
|
|
1 |
C100 |
Germany |
P100 |
|
|
2 |
C200 |
USA |
P300, P400 |
|
|
3 |
C300 |
Morocco |
P500 |
|
|
4 |
C400 |
Spain |
P200, P700 |
|
|
5 |
C500 |
South Africa |
P600, P800, P900 |
|
- add the cellSplitter script to the flow
- connect to the Tableau Python (TabPy) server
- locate the .py file that contains the cellSplitter function
- enter the function name, ‘cellSplitter.’
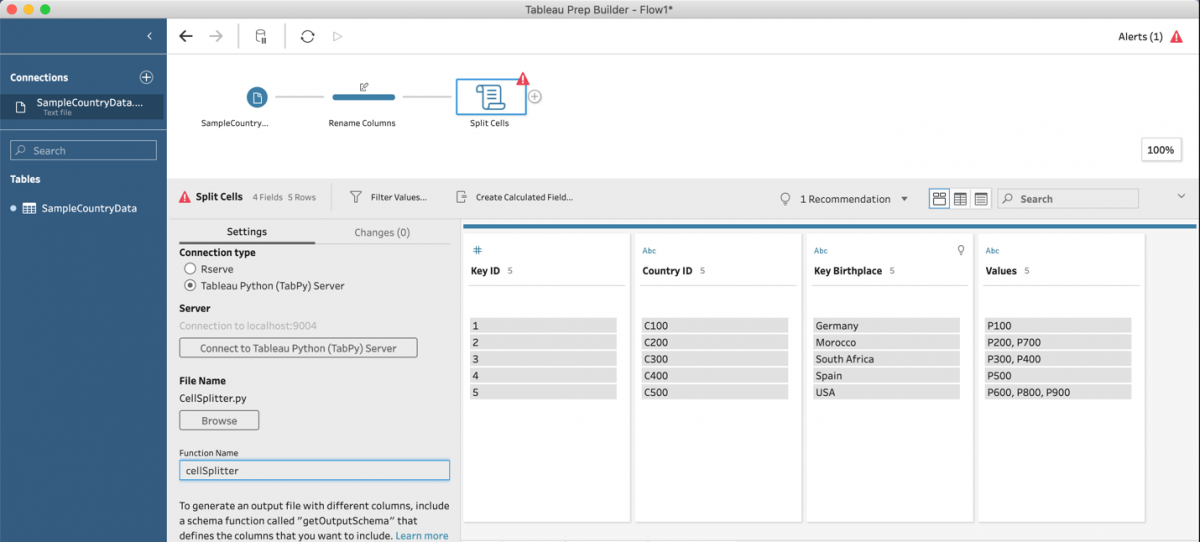
- hit enter and the results will be returned as an expanded version of the ‘Values’ column:
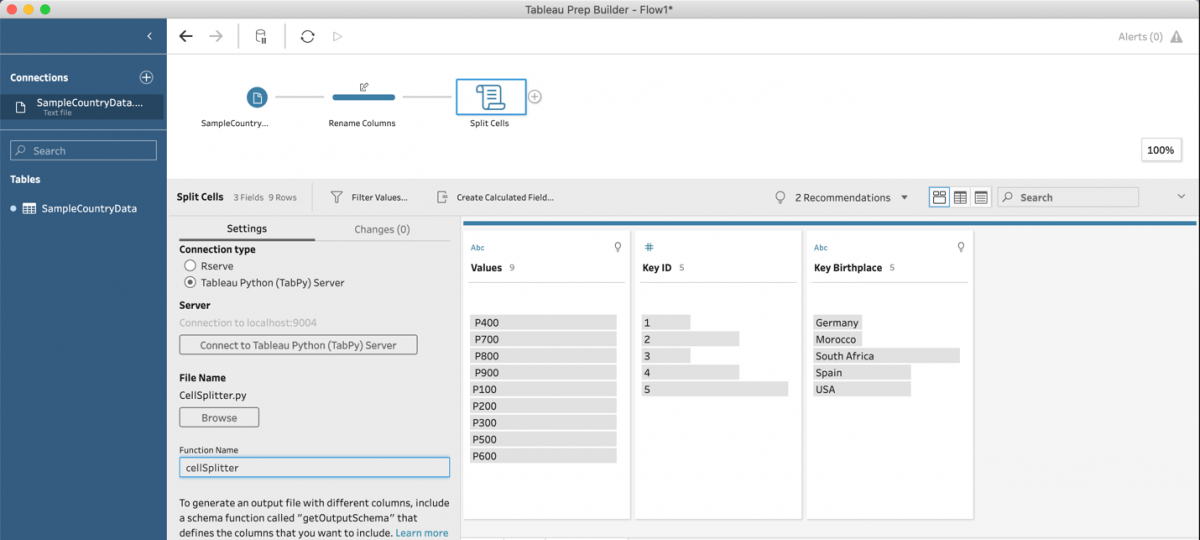
- rename the columns back to the original names (directly in the Script step w/o an additional Clean Step)
|
ID |
Birthplace |
Person ID |
|
1 |
Germany |
P100 |
|
2 |
USA |
P300 |
|
2 |
USA |
P400 |
|
3 |
Morocco |
P500 |
|
4 |
Spain |
P200 |
|
4 |
Spain |
P700 |
|
5 |
South Africa |
P600 |
|
5 |
South Africa |
P800 |
|
5 |
South Africa |
P900 |
Benefits of this Approach
- handles input of variable number of values in a single cell without data loss (huge win!)
- extremely quick
- can expand 10,000 values in a single cell in under two seconds running on a laptop
- once Script step names are configured returns the split data almost immediately
- results are returned efficiently and accurately, within moments of execution
- tested on extremely large datasets with millions of values
Want to add this capability to your flow?
Download the CellSplitter Python script: ai_cell-splitter_v1.py.
This script takes advantage of an undocumented but important feature. Tableau passes an empty data frame as an argument to get output schema() so you can tell what columns the user’s data frame contains. (It would be helpful if Tableau updated the documentation to include this detail)
Download a command line utility script to split .csv files: ai_cmdline_cell_splitter_v1.py
The command line script takes two required arguments to specify the input data file and the name of the column to split:
$ python CmdLineCellSplitter.py My_Data_File.csv My_Target_Column
Also, the command line script can take additional optional arguments to specify the delimiter character, a new name for the target column if you would like to rename it, and any additional column names that you would like to be preserved in the output data.
Download and equivalent R script, cellSplitter, using the cSplit() function in R’s splitstackshape package: ai_cell-splitter_v1.r
The only difference between this script and the Python script is that you will need to setup and install Rserve instead of TabPy. I recommend installing Rserve through RForge, rather than the CRAN, because this guarantees the latest version, eliminating errors.
This installation is trivial and can be completed by running the following code in R:
install.packages("Rserve",,"http://rforge.net").
To start the server, in your command line enter: $ R CMD Rserve
Connect in Tableau Prep, select the Rserve server. The default host is ‘localhost’ and the default port is 6311.
Conclusion
Tableau Prep would be even more useful if it allowed users to pass arguments to scripts to configure their behavior and in my case, avoid the need to rename columns. Please help get argument passing features on Tableau’s radar by upvoting the idea on Tableau’s community forum: https://community.tableau.com/s/idea/0874T000000HBwDQAW/detail
I would like to thank Alex Blakemore for giving me the inspiration for this project and providing feedback on my solution and also my APOGEE colleagues, Geoff Lucas and Michael Harmon, for their support and advice.
I hope you find this useful!

Sara Carlin
June 4, 2020
Apogee Integration, LLC (APOGEE) focuses on Enterprise Engineering & Data Science supporting U.S. defense and national security clients and is a Tableau Services Partner. Out experienced certified engineers, analysts, developers, system architects and data scientists love helping clients discover the messages in their data and solve their mission critical problems. Email dataviz@apogeeintegration.com to start a dialog on how APOGEE might assist your project. To learn more about careers: Become an APOGEE-nius